Visual Analytics Final Project
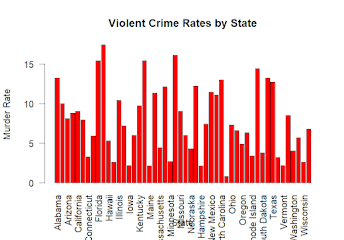
Title: Exploring Violent Crime Rates in the United States: Insights from the USArrests Dataset Introduction Welcome to the exploration of violent crime rates in the United States using the "USArrests" dataset. In this blog post, we'll delve into the dynamics of violent crime across different states, exploring factors such as demographics, geographical patterns, and correlations between variables. Problem Statement The objective is to understand the factors influencing violent crime rates and identify patterns or trends that may exist across different states. By analyzing the "USArrests" dataset, the aim is to gain insights into the underlying drivers of violent crime in the United States. Related Work The analysis builds upon previous studies in criminology and data analytics. Similar research has explored the relationship between socio-economic factors and crime rates. We'll leverage existing visual analytics techniques, such as correlation matrices, to e...


